 Payara Micro jest lekkim serwerem aplikacji, stworzonym w oparciu o GlassFish 4.1 ze wsparciem Java EE 7. Zajmując zaledwie 70 MB, serwer wyposażony został w mechanizmy automatycznego klastrowania Hazelcast, dystrybucję pamięci podręcznej Payara JCache, proste zarządzanie umożliwiające uruchamianie aplikacji .war bezpośrednio z linii komend, bez instalacji serwera aplikacji, wyposażonym we wbudowane API Java. Payara Micro został zoptymalizowany pod kątem nowoczesnej infrastruktury opartej o kontenery. W prosty sposób może zostać zaimplementowany w chmurze, dostarczając zautomatyzowane klastrowanie aplikacji opartych o Java EE.
Payara Micro jest lekkim serwerem aplikacji, stworzonym w oparciu o GlassFish 4.1 ze wsparciem Java EE 7. Zajmując zaledwie 70 MB, serwer wyposażony został w mechanizmy automatycznego klastrowania Hazelcast, dystrybucję pamięci podręcznej Payara JCache, proste zarządzanie umożliwiające uruchamianie aplikacji .war bezpośrednio z linii komend, bez instalacji serwera aplikacji, wyposażonym we wbudowane API Java. Payara Micro został zoptymalizowany pod kątem nowoczesnej infrastruktury opartej o kontenery. W prosty sposób może zostać zaimplementowany w chmurze, dostarczając zautomatyzowane klastrowanie aplikacji opartych o Java EE.
Dla UniCloud przygotowane zostały wstępnie skonfigurowane paczki oprogramowania, dzięki czemu integracja rozwiązania z platformą przebiega gładko i szybko. Zawarto w nich wszystkie wymagane kroki instalacyjne pozwalające uzyskać kilkoma kliknięciami w pełni funkcjonalny i skalowalny klaster Payara Micro.
Implementacja Payara Micro w UniCloud
Pakiet Payara Micro został przygotowany z wykorzystaniem minimalnej ilości węzłów (kontenerów), zawiera jednak wszystkie wymagane narzędzia pozwalające na skalowanie horyzontalne, pozwalające na elastyczne przyjęcie zwiększonego ruchu.
 Rozwiązanie zostało zbudowane z kontenerów Docker, z wykorzystaniem następujących obrazów:
Rozwiązanie zostało zbudowane z kontenerów Docker, z wykorzystaniem następujących obrazów:
- jelastic/payara-micro-cluster – serwer aplikacji Payara Micro (domyślnie zainstalowana zostaje jedna instancja, automatycznie skalowalna poziomo w przypadku wzrostu obciążenia)
- jelastic/haproxy-managed-lb –równoważenie obciążenia za pomocą HAProxy, który automatycznie dodaje/usuwa serwery aplikacyjne w plikach konfiguracyjnych load balancera, gdy ich ilość się zmienia
- jelastic/storage –dedykowany kontener typu data storage, domyślnie zawiera prostą aplikację do symulacji obciążeń, pozwalającą na przetestowanie możliwości skalowania klastra
Główną korzyścią, wynikającą z korzystania z platformy UniCloud jest możliwość korzystania z prekonfigurowanych pakietów, które skalują się automatycznie (domyślnie do 16 cloudletów, czyli do 6400 MHz CPU i 2046 GB RAM), w zależności od obciążenia. Dzięki temu zasoby zużywane są tylko w takim zakresie, jaki jest niezbędny.
Dodatkowo, wszystkie serwery w klastrze posiadają możliwość wysyłania alertów, gdy obciążenie kontenerów zbliża się do zadeklarowanej granicy. Wszystkie te parametry można dostosować do swoich potrzeb.
Szybka instalacja klastra Payara Micro
Instalacja klastra Payara Micro jest procesem zautomatyzowanym, sprowadza się do importu odpowiedniego projektu z GitHub:
- W panelu UniCloud wybierz IMPORT pliku manifest.jps z adresu URL:
https://github.com/jelastic-jps/payara/blob/master/payara-micro-cluster-advanced/manifest.jps
Aby kontynuować, kliknij Import na dole okienka:
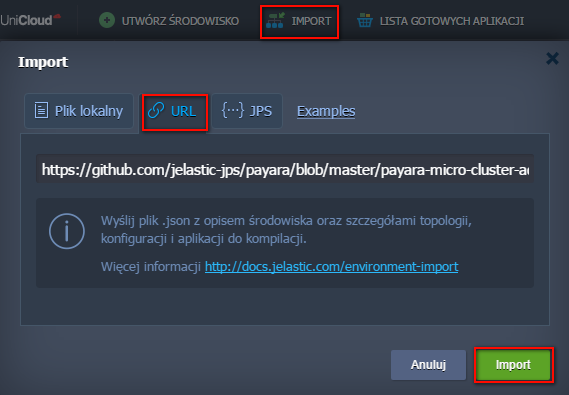
- W oknie, które się pojawi, wprowadź podstawowe parametry środowiska, które tworzysz:
Środowisko: nazwa wybrana dla domeny wewnętrznej
Display Name: alias środowiska wyświetlany w panelu UniCloud
Region: preferowany region (jeśli opcja jest dostępna), następnie naciśnij Zainstaluj.

- Odczekaj, aż pakiety zostaną dostarczone,
 a klaster skonfigurowany:
a klaster skonfigurowany:

Operacje przebiegły w sposób zautomatyzowany i zakończyły się utworzeniem kompletnego, skonfigurowanego, gotowego do pracy środowiska:
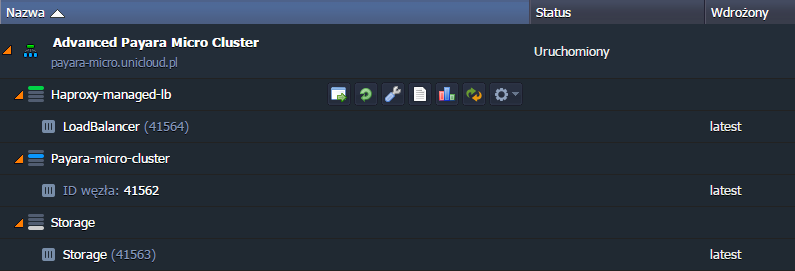
Testowanie i skalowanie klastra
Zaprezentowane rozwiązanie wyposażone zostało we wbudowaną aplikację do testowania obciążenia procesora i pamięci. Narzędzie zostało umieszczone w kontenerze Storage i jest automatycznie montowane po instalacji klastra.
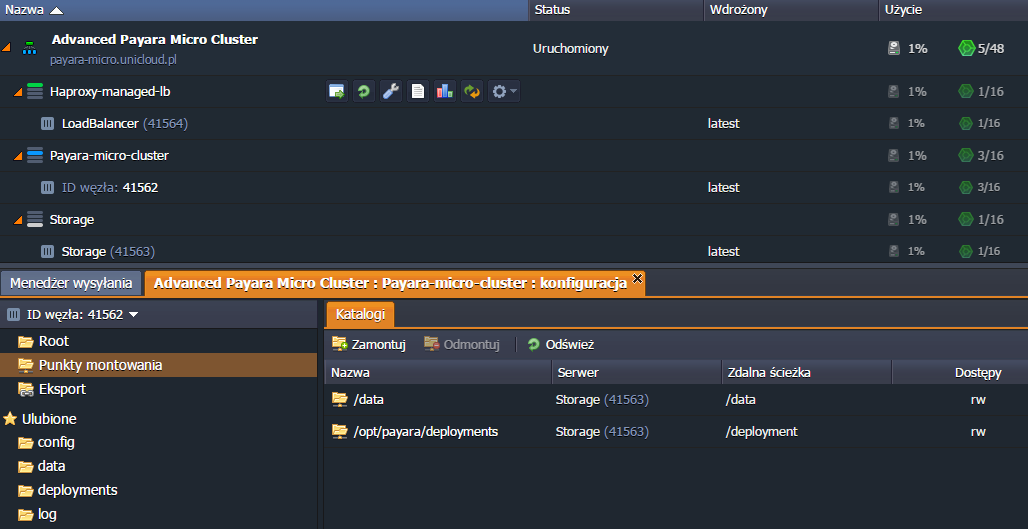 Przy jego pomocy można odkryć możliwości skalowania klastra i zaobserwować jego zachowanie w przypadku zmiany obciążenia. Aby uruchomić test, wprowadź link:
Przy jego pomocy można odkryć możliwości skalowania klastra i zaobserwować jego zachowanie w przypadku zmiany obciążenia. Aby uruchomić test, wprowadź link:
http://{env.domain}/loader
 W zależności od rodzaju zasobów, które chcesz przetestować, wprowadź odpowiednie parametry do zasymulowania obciążenia (RAM lub CPU), wypełniając odpowiednio
W zależności od rodzaju zasobów, które chcesz przetestować, wprowadź odpowiednie parametry do zasymulowania obciążenia (RAM lub CPU), wypełniając odpowiednioLoad – ilość symulowanych zasobów (% użycia dla RAM lub ilość wątków dla CPU)
Duration – czas trwania testu w sekundach
Naciśnij RUN w odpowiedniej sekcji. Przetestujemy obciążenie kolejno, z parametrami takimi, jak powyżej, aby zbadać, jaki będą miały wpływ na środowisko:Test CPU zostanie uruchomiony dla 2 wątków, aby zasymulować obciążenie wywołane przez kilku użytkowników i zweryfikować, jak zachowa się automatyczne skalowanie pionowe.
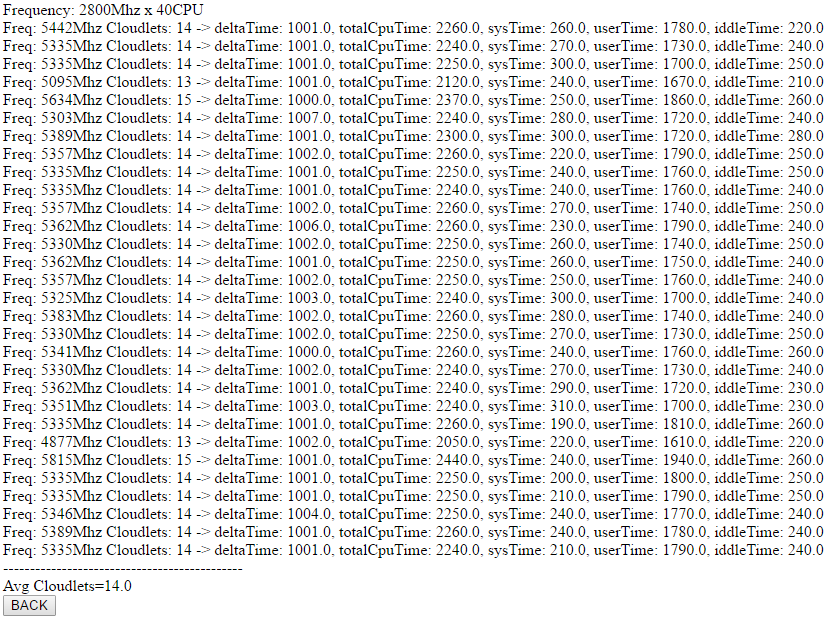 W naszym przypadku średnie obciążenie wyniosło 14 cloudletów, co odpowiada użyciu około 5600 MHz procesora.
W naszym przypadku średnie obciążenie wyniosło 14 cloudletów, co odpowiada użyciu około 5600 MHz procesora.
Dla testu RAM zadeklarujemy użycie 80% pamięci, co spowoduje zwiększenie ilości instancji Payara Micro, po włączeniu automatycznego skalowania poziomego.
 Po zakończeniu ładowania, można zaobserwować pojawienie się wpisu „Calling GC„, co oznacza uruchomienie Garbage Collection, będącego częścią testu. Narzędzie automatycznie wykrywa i zwalnia niepotrzebną zawartość pamięci.
Po zakończeniu ładowania, można zaobserwować pojawienie się wpisu „Calling GC„, co oznacza uruchomienie Garbage Collection, będącego częścią testu. Narzędzie automatycznie wykrywa i zwalnia niepotrzebną zawartość pamięci.
Aby zobaczyć wynik testu, można wywołać okno Statystyki dla klastra Payara i śledzić wizualizację zmian obciążenia na wykresach. Należy mieć na uwadze, że wykresy są tworzone na podstawie wartości średnich w danych interwałach i chwilowe piki obciążenia mogą nie zostać odnotowane.
 Wykres obciążenia procesora (po lewej) odpowiada obciążeniu, które może zostać obsłużone przez pojedynczy kontener Payara Micro. Na wykresie użycia pamięci RAM (po prawej) można odczytać wartość maksymalną oscylującą w okolicy 1500 MB, co powoduje wyzwolenie inicjatora włączenia skalowania poziomego, czyli innymi słowy zwiększenie ilości kontenerów Payara Micro
Wykres obciążenia procesora (po lewej) odpowiada obciążeniu, które może zostać obsłużone przez pojedynczy kontener Payara Micro. Na wykresie użycia pamięci RAM (po prawej) można odczytać wartość maksymalną oscylującą w okolicy 1500 MB, co powoduje wyzwolenie inicjatora włączenia skalowania poziomego, czyli innymi słowy zwiększenie ilości kontenerów Payara Micro
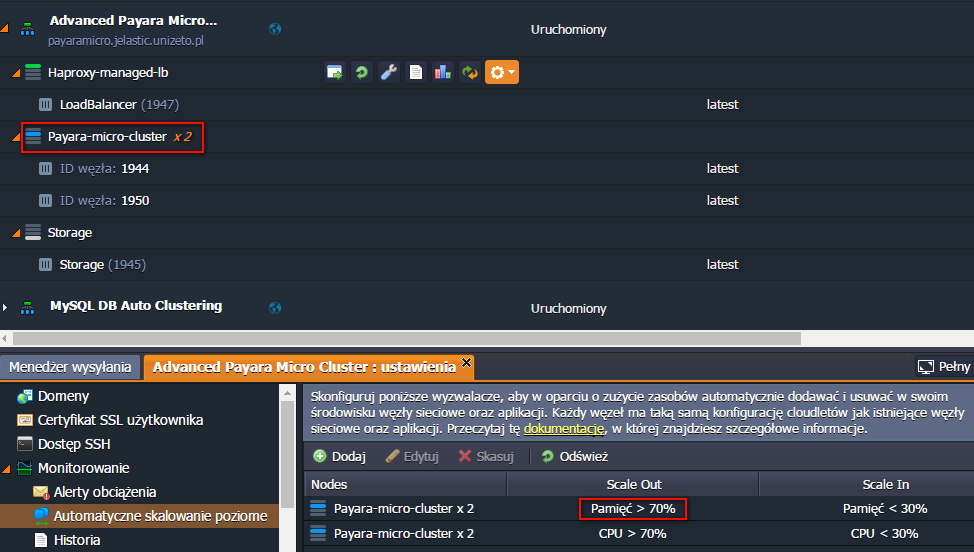 Po zakończeniu naszego testu i zmniejszeniu obciążenia, ilość kontenerów zostanie automatycznie zredukowana. O wszystkich tych zdarzeniach zostaniemy poinformowani również za pomocą wiadomości e-mail,
Po zakończeniu naszego testu i zmniejszeniu obciążenia, ilość kontenerów zostanie automatycznie zredukowana. O wszystkich tych zdarzeniach zostaniemy poinformowani również za pomocą wiadomości e-mail,
po zwiększeniu obciążenia:
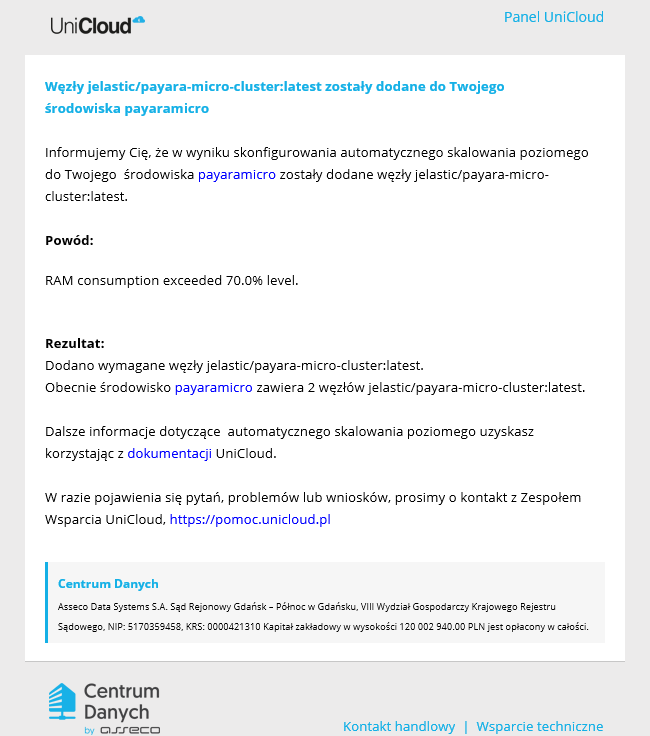 oraz po jego spadku:
oraz po jego spadku:

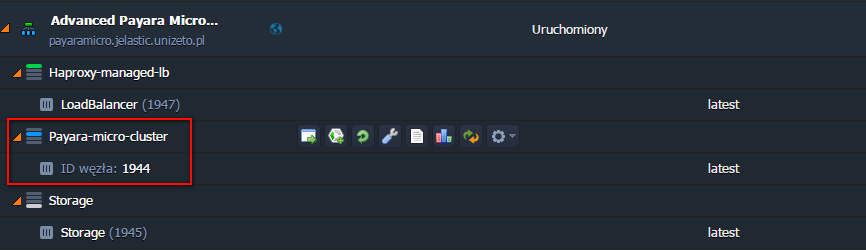
Jak widać, po spadku obciążenia do zadanego poziomu, platforma automatycznie zredukowała ilość węzłów do zadanej (minimalnej) wielkości.
Parametry skalowania i warunki brzegowe można oczywiście dostosować do swoich potrzeb. Zmianę skalowania można przeprowadzić wybierając dla środowiska kolejno: Ustawienia -> Monitorowanie -> Automatyczne skalowanie poziome
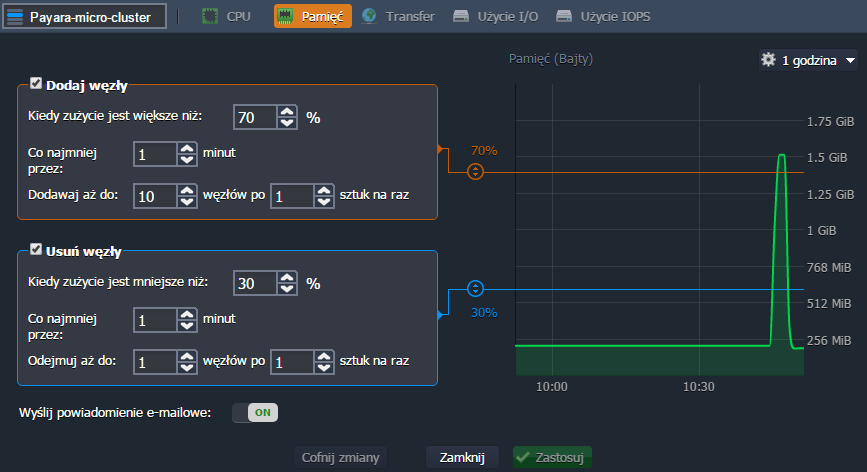
Historię zdarzeń można również prześledzić za pomocą wbudowanego narzędzia, które dla środowiska, w Ustawienia -> Monitorowanie -> Historia -> Skalowanie poziome przechowuje dane o zaistniałych przypadkach przeprowadzenia automatycznych operacji skalowania (zarówno dodawania, jak i usuwania węzłów):
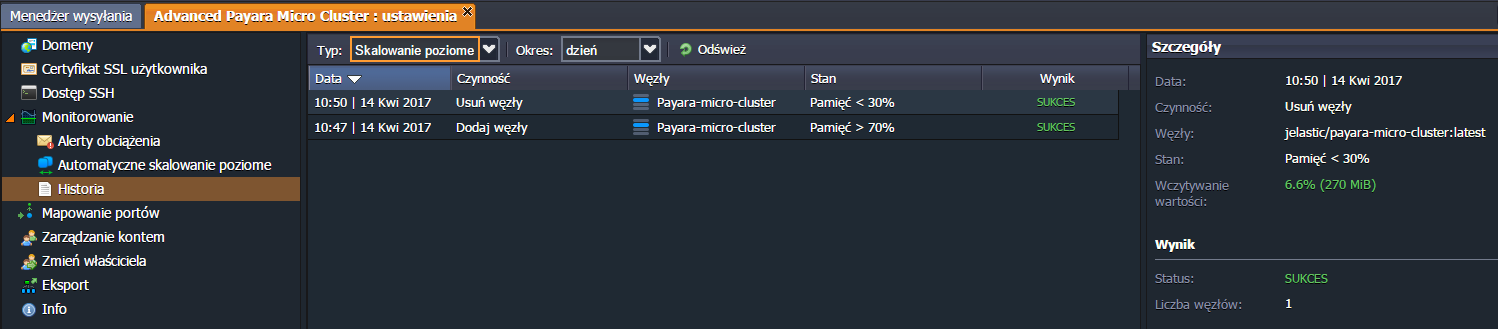 Na tym przykładzie możemy zaobserwować, że po zwiększeniu obciążenia pamięci ponad 70% został dodany jeden węzeł, a po spadku obciążenia poniżej 30% węzeł ten został usunięty i środowisko powróciło do wielkości pierwotnej.
Na tym przykładzie możemy zaobserwować, że po zwiększeniu obciążenia pamięci ponad 70% został dodany jeden węzeł, a po spadku obciążenia poniżej 30% węzeł ten został usunięty i środowisko powróciło do wielkości pierwotnej.
Jeśli chcemy dowiedzieć się, co dzieje się w klastrze podczas skalowania, możemy zajrzeć do sekcji Log, gdzie przejrzymy m.in.
– lb_manager.log – jakie węzły zostały dodane/usunięte dla zrównoważenia obciążenia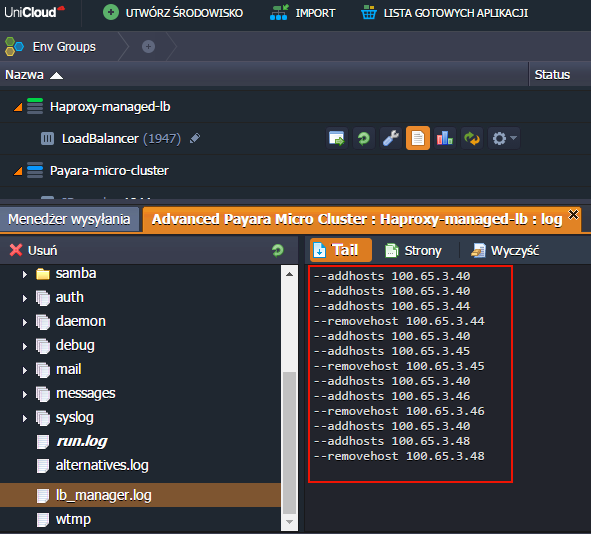
– run.log wewnątrz serwera aplikacji dla śledzenia bieżącej aktywności klastra
 Wszystkie te zabiegi mają na celu zapewnienie, że aplikacje Java, uruchamiane wewnątrz klastra Payara, będą w stanie obsłużyć zróżnicowaną ilość ruchu przychodzącego, bez konieczności monitorowania jego zmian. Co więcej, ze względu na zautomatyzowanie dodawania zasobów, wydajność rozwiązania będzie najwyższa, gdyż w okresie wzrostu obciążenia, dla aplikacji będzie dostępne więcej zasobów, a w okresie bezczynności środowisko zwolni zasoby niepotrzebne. Eliminujemy w ten sposób konieczność ręcznej rekonfiguracji i zarazem potencjalne źródło problemów i błędów.
Wszystkie te zabiegi mają na celu zapewnienie, że aplikacje Java, uruchamiane wewnątrz klastra Payara, będą w stanie obsłużyć zróżnicowaną ilość ruchu przychodzącego, bez konieczności monitorowania jego zmian. Co więcej, ze względu na zautomatyzowanie dodawania zasobów, wydajność rozwiązania będzie najwyższa, gdyż w okresie wzrostu obciążenia, dla aplikacji będzie dostępne więcej zasobów, a w okresie bezczynności środowisko zwolni zasoby niepotrzebne. Eliminujemy w ten sposób konieczność ręcznej rekonfiguracji i zarazem potencjalne źródło problemów i błędów.
Zapraszamy do samodzielnego przetestowania rozwiązania.
